note · 2,467 字
RocketMQ
RocketMQ:消息模型、顺序消费、不丢失不重复、积压处理。
MQ笔记
RocketMQ
- 应用解耦
- 异步提速
- 削峰填谷
消息队列模型
- Producer Group
- Consumer Group
- MessageQueue (kafka中的
Partition) - Topic
- Broker 消息存储与转运节点
如何保证顺序消费
“关于顺序消费,核心思想是将全局有序降级为局部有序。具体来说,可以分为两步来实现:
第一步是在发送端: 比如我们要处理同一个订单的‘创建、支付、发货’这三个步骤。在发送消息时,我们会提取订单 ID 作为业务 Key,通过 Hash 取模的方式,强制把这三个强关联的消息路由到 Broker 上的同一个分区Partition中。
第二步是在消费端: 因为消息中间件底层的机制通常保证同一个分区在同一时刻只能被单个实例拉取,所以我们在 Java 或 Go 的后端服务中拉取到消息后,只要保证用单线程(或单 Goroutine)去串行处理这个队列的数据,就能严格保证这三个步骤的执行顺序了。”
高效读写原理
数据和索引分离
CommitLog:预申请内存空间确保消息连续存储高效读写- ConsumeQueue:这是一个消息的逻辑索引文件。它不存消息全量数据,只存固定长度的条目,包含消息在
CommitLog中的物理偏移量、大小等信息。消费者消费时,会先读取ConsumeQueue这个轻量级的索引,然后再根据偏移量去CommitLog中读取完整的消息。 〔图片缺失:本地路径不可用〕
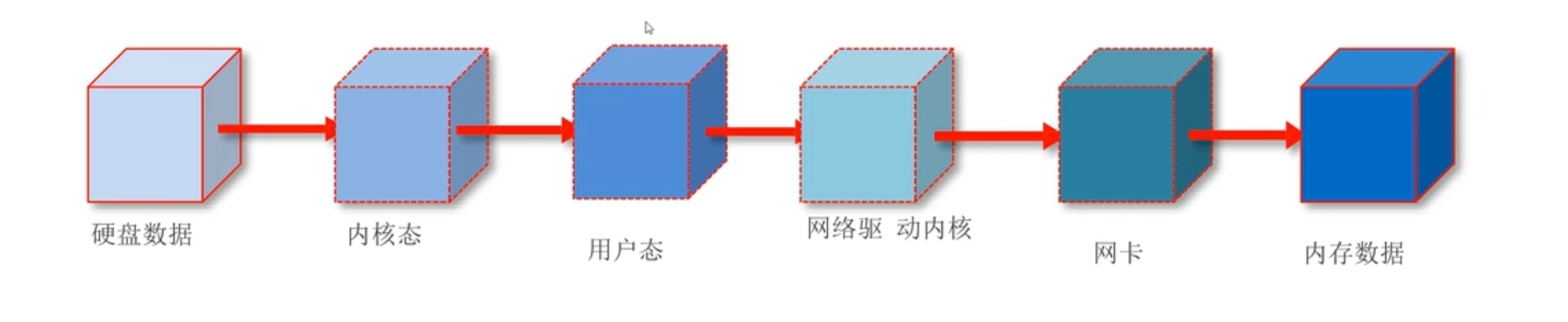
零拷贝技术
- 在消费消息时,数据可以直接从页缓存发送到网卡,无需经过应用程序的用户态内存,减少了数据拷贝次数和上下文切换,极大地提升了消息的消费效率。
刷盘机制
- 同步刷盘
- 当消息被写入内存的页缓存后,必须等待数据成功刷入磁盘后,才会向生产者返回成功的 ACK。
- 优点:可靠性最高。即使 Broker 所在机器宕机,只要生产者收到了成功响应,这条消息就一定不会丢失。
- 缺点:性能最低,因为每次写入都需要等待一次磁盘 I/O。
- 适用场景:对数据可靠性要求极高的场景,如金融交易、核心订单系统。
- 异步刷盘 (Asynchronous Flush):
- 流程:消息只要成功写入内存的页缓存,就立刻向生产者返回成功的 ACK。之后由一个后台线程异步地、批量地将页缓存中的数据刷入磁盘。
- 优点:性能最高,吞吐量最大。
- 缺点:可靠性稍低。如果 Broker 机器在刷盘前断电或宕机,页缓存中尚未刷盘的消息将会丢失。
- 适用场景:绝大多数互联网应用,如日志收集、短信通知等,能容忍在极端故障下丢失少量数据。这是 RocketMQ 默认的刷盘方式。
死信队列
当一条消息在初次消费失败后,RocketMQ 会自动进行重试。如果经过了预设的重试次数(默认16次)后,消息依然消费失败,那么这条消息就不会再被投递,而是会被发送到一个特殊的队列(归属于某一个组)——死信队列。
如何保证消息不丢失
- 生产者端不许确认消息落地
- ACK确认机制
- 重试机制
- Broker端
- 多副本架构 每个partition有多个副本
- 消费者端
- 消息还没处理完,程序就自动提交了位移(Offset),紧接着程序挂了。 重启后,Kafka 以为你已经处理过了,直接从下一个位移开始,导致消息“漏处理”。
- 手动确认消费
消费者端如何不重复消费?
- 不重复消费 - 消费端的逻辑上
- 必须实现消费的幂等性,利用业务唯一标识等
- 幂等性指的是对于同一个操作,执行一次和执行多次的结果是完全相同的,不会因为重复执行而产生副作用。
- 1 数据库唯一索引
- 2 基于Redis的分布式锁'
- 每条消息都带有一个唯一的
Message ID或业务单号。消费者拿到消息后,先去 Redis 执行SETNX(MessageID, 1)。 - 如果返回成功(代表不存在),说明是第一次消费,放行执行后续业务。
- 如果返回失败(代表已存在),说明这条消息被处理过了,直接丢弃
- 每条消息都带有一个唯一的
- 3 乐观锁 基于版本号
- 4 业务状态机
消息队列积压如何处理
紧急止血恢复业务 - 排查原因 - 优化架构预防
- 紧急救火
- 临时扩容消费者
- 紧急中转 写一个及其简单的分发消费者 作用是拉去消息队列投递到一个新建的Topic中
- 服务降级与丢弃策略 扔掉一些非核心数据
- 排查原因
- 优化架构 长期预防
- 死信队列
- 优化消费逻辑
- 完善监控与告警体系
RocketMQ和Kafka如何选择
| 特性 | Kafka | RocketMQ |
|---|---|---|
| 设计初衷 | 大数据/日志流处理。追求极致的吞吐量。 | 业务/金融级消息。追求高可靠与丰富业务功能。 |
| 单机吞吐量 | 极高。百万级(基于零拷贝和顺序写)。 | 高。十万级(接近 Kafka,但在海量 Topic 下更稳定)。 |
| 消息可靠性 | 较强(支持同步/异步刷盘)。 | 极强(专门为金融交易设计,支持完善的重试机制)。 |
| Topic 支持 | 有限。单机几百个 Topic 后性能大幅下降。 | 海量。单机可支持上万个 Topic,性能波动小。 |
| 业务功能 | 基础功能为主。 | 极其丰富。支持事务消息、延迟消息、死信队列等。 |
| 运维门槛 | 较高(需管理 ZooKeeper 或 KRaft)。 | 较低(NameServer 轻量级且无状态)。 |