乐享生活
基于 Redis 的实战项目:登录、秒杀、缓存、UV 统计、附近商户、关注等。
乐享生活
类似于大众点评,实现了短信登录、商户查询缓存、优惠卷秒杀、附近的商户、UV统计、用户签到、好友关注、达人探店、Ai推荐九个功能。
- 使用Redis解决了在集群模式下的Session共享问题,使用拦截器实现了用户的登录校验和权限刷新。
- 使用Redis对高频访问信息进行缓存,解决了缓存穿透、缓存击穿、缓存雪崩问题。
- 使用Redis + Lua脚本实现对用户秒杀资格的预检,同时用乐观锁解决秒杀产生的超卖问题
- 使用Redis的 ZSet 数据结构实现了点赞排行榜功能,使用Set 集合实现关注、共同关注功能
框架
Controller
- @RestController
- @RequestMapping
Service
- @Service
- Interface - extends IService
- Imp - extends ServiceImp<UserMapper, User>
Mapper
- @Mapper
- extends BaseMapper(User)
token,session,cookie的区别?
Cookie
- 存储在客户端
- 有篡改风险 容量有限 用户可禁用
Session
- 存储在服务端
- 占用服务资源 分布式条件下引用困难
Token - JWT Json-Web-Token
- Header PayLoad Signature
只防伪 不防盗
{
"alg": "HS256",
"typ": "JWT"
}{
"sub": "user-123",
"name": "John Doe",
"role": "admin",
"exp": 1678886400
}将编码后的 Header、编码后的 Payload 和 Secret 组合起来进行哈希运算:
HMACSHA256(base64UrlEncode(header) + "." + base64UrlEncode(payload), secret)
登录
当注册完成后,用户去登录会去校验用户提交的手机号和验证码,是否一致,如果一致,则根据手机号查询用户信息,不存在则新建,最后将用户数据保存到redis,并且生成token作为redis的key,当我们校验用户是否登录时,会去携带着token进行访问,从redis中取出token对应的value,判断是否存在这个数据,如果没有则拦截,如果存在则将其保存到threadLocal中,并且放行。
用户脱敏的处理
一个是刚开始在数据传输的过程中,用户的所有信息均在浏览器中传递,过于敏感,不太安全。
所以将部分可展示属性封装成单独的DTO进行传递。
其次是对于用户手机号作为key传播储存的替换,我们在后台生成一个随机串token,然后让前端带来这个token就能完成我们的整体逻辑了。
发送验证码
- 验证手机号格式
- 生成验证码 Random 或 服务商
- 保存至Redis
- key login:code + phone
- ttl 过期时间
登录
- 校验手机号
- 校验验证码
- 判断用户是否存在
- 生成Token
- 将User转化为HashMap存储在Redis中
拦截器
//Token刷新拦截器
registry.addInterceptor(new RefreshTokenInterceptor(stringRedisTemplate)).addPathPatterns("/**").order(0);
//登录拦截器 if userHolder.getUser==null return false
registry.addInterceptor(new LoginInterceptor())
.excludePathPatterns(
"/user/login",
"/user/code",
"/blog/hot/**",
"/upload/**",
"/shop-type/**",
"/voucher/**",
"/shop/**"
).order(1);商户缓存功能
在查询商户信息时,往往通过缓存来提升访问速度。
标准的操作方式就是查询数据库之前先查询缓存,如果缓存数据存在,则直接从缓存中返回,如果缓存数据不存在,再查询数据库,然后将数据存入redis。
双写一致问题
根据id查询店铺时,如果缓存未命中,则查询数据库,将数据库结果写入缓存,并设置超时时间
在本环境下,弱一致性要求。根据id修改店铺时,先修改数据库,再删除缓存。等下一次再来查询数据时,再从数据库中加载到缓存中。
缓存穿透问题及解决方案
客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。庞大的请求导致服务端宕机等损害。
- 缓存空对象
- 布隆过滤器
布隆过滤器实现较为复杂所以就用了缓存空对象的方法。
缓存雪崩问题及解决思路
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
- Key 随机TTL
- 给缓存业务添加降级限流策略
- 降级就是牺牲一些不重要的功能
- 分布式Redis集群
缓存击穿问题及解决思路
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
- 互斥锁 - 查询数据库的互斥锁 只能由一个线程查询
- 逻辑过期
优惠券秒杀功能
redis实现全局唯一ID、优惠券秒杀解决单体架构的一人一单问题、乐悲观锁使用等等
最开始的方案
超卖问题 - CAS
重复下单问题 单体锁(分布式锁) (Redisson(取代setnx))
RLock lock = redissonClient.getLock("lock:order:" + userId);实际方案
- 通过Lua脚本校验秒杀资格(库存数量,是否重复下单,将下单用户存在Set集合)
- 将有资格的订单发送至Stream消息队列,处理后续生成订单操作,在线程池中异步处理订单。
- 提交订单 查询数据库用户是否已经购买过
- 对数据库使用CAS防止超卖问题(Redis中有一个库存,秒啥时候检测用,Mysql中也有一个
附近的商户
- 判断是否需要基于地理位置进行搜索。如果不需要,就直接查数据库;
- 如果需要,则先用 Redis 的 GEO 功能高效地筛选出附近指定数量的商铺ID和距离,
- 根据这些ID去数据库查询完整的商铺信息
- 将距离信息附加到结果中返回。
- 这样做可以大大减轻数据库在处理大量地理位置排序计算时的压力。
UV统计
Unique Visitor(独立访客)
HyperLogLog 是一种概率数据结构,非常节省内存,它占用的内存通常都固定在 12KB 左右。
用户签到
BitMap
当用户点击签到时,程序会找到代表该用户本月签到记录的 Redis Key,然后将这个 Key 中代表“今天”的那个二进制位(bit)设置为 1,从而完成签到。
好友关注
- Set作用:
- 作为关注列表的缓存,快速判断某人关注了哪些人。
- 利用 Set 的特性进行高效的关系运算,比如求交集(共同关注)。
达人探店
- Feed流
- Feed流 基于ZSet实现
- 推模型 博主写博客推给粉丝
- 拉模型
- 点赞
- 点赞也是用Zset实现
- 每个博客有一个Redis Zset存储点赞的用户
- 在数据库层面记录点赞数量
1. 发布博客与粉丝推送 (Feed Push/Fan-out)
这是 saveBlog 方法的逻辑,采用的是“写扩散”(Fan-out on Write),也叫“推模型”(Push Model)。
- 保存博客到数据库:当用户发布一篇新博客时,首先将博客内容保存到数据库(如MySQL)中。
- 获取粉丝列表:从数据库中查询出发布者所有的粉丝。
- 推送给粉丝:遍历粉丝列表,将这篇新博客的 ID 推送到每一个粉丝的 Redis "收件箱" 中。
- 这个"收件箱"是一个 ZSet,Key 的格式为
feed:粉丝ID。 - ZSet 的
value是博客 ID。 - ZSet 的
score是博客发布的时间戳。
- 这个"收件箱"是一个 ZSet,Key 的格式为
优点:粉丝在读取自己的 Feed 流时,只需直接从自己的 "收件箱" (ZSet) 中读取,速度极快,因为内容已经提前准备好了。
2. 点赞 / 取消点赞 (likeBlog 方法)
这个功能同样是数据库和 Redis 结合,用 ZSet 实现了高性能的点赞列表。
- 判断点赞状态:
- 使用 Redis ZSet (
BLOG_LIKED_KEY + 博客ID) 来存储所有点赞了这篇博客的用户。 value是用户 ID,score是点赞的时间戳。- 通过
zscore命令检查当前用户是否已在该 ZSet 中,从而判断是否已点赞。
- 使用 Redis ZSet (
- 执行操作:
- 如果未点赞:
- 数据库中对应博客的
liked字段加 1。 - 将当前用户的 ID 添加到 Redis 的 ZSet 中,
score为当前时间戳。
- 数据库中对应博客的
- 如果已点赞:
- 数据库中
liked字段减 1。 - 将当前用户的 ID 从 Redis 的 ZSet 中移除。
- 数据库中
- 如果未点赞:
优点:利用 ZSet 可以快速判断用户是否点赞,并且可以根据时间戳(score)轻松实现“最早点赞的N个人”这类需求。
3. 查看关注人的博客Feed流 (queryBlogOfFollow 方法)
这是对第1点“推送”逻辑的“消费”,实现了滚动分页(Infinite Scroll)。
- 获取当前用户收件箱:直接从 Redis 中找到当前用户的 "收件箱" ZSet (
feed:userId)。 - 滚动分页查询:
- 使用
ZREVRANGEBYSCORE命令,按score(时间戳) 倒序分页拉取数据。 - 客户端请求时会带上上一页最后一条博客的时间戳 (
max) 和一个偏移量 (offset)。 - 这样可以高效地拉取“比某个时间更早”的一页博客ID。
- 使用
- 解析与数据填充:
- 从 Redis 拿到博客 ID 列表后,再去数据库中一次性查询这些博客的详细内容。
- 为每篇博客填充作者信息和当前用户的点赞状态(
isBlockLiked方法)。
- 返回结果:返回博客列表,以及用于下一次分页的
minTime和offset。
Ai推荐
Memory (**ChatMemory**) 记忆组件ChatMemoryStore接口 将 List<ChatMessage> 序列化成 JSON 字符串,然后存入数据库。
隔离机制:通过一个 memoryId 对象实现。
Tools (**@Tool**): 工具集 让 AI 能够调用外部 API 来获取附近的餐厅数据
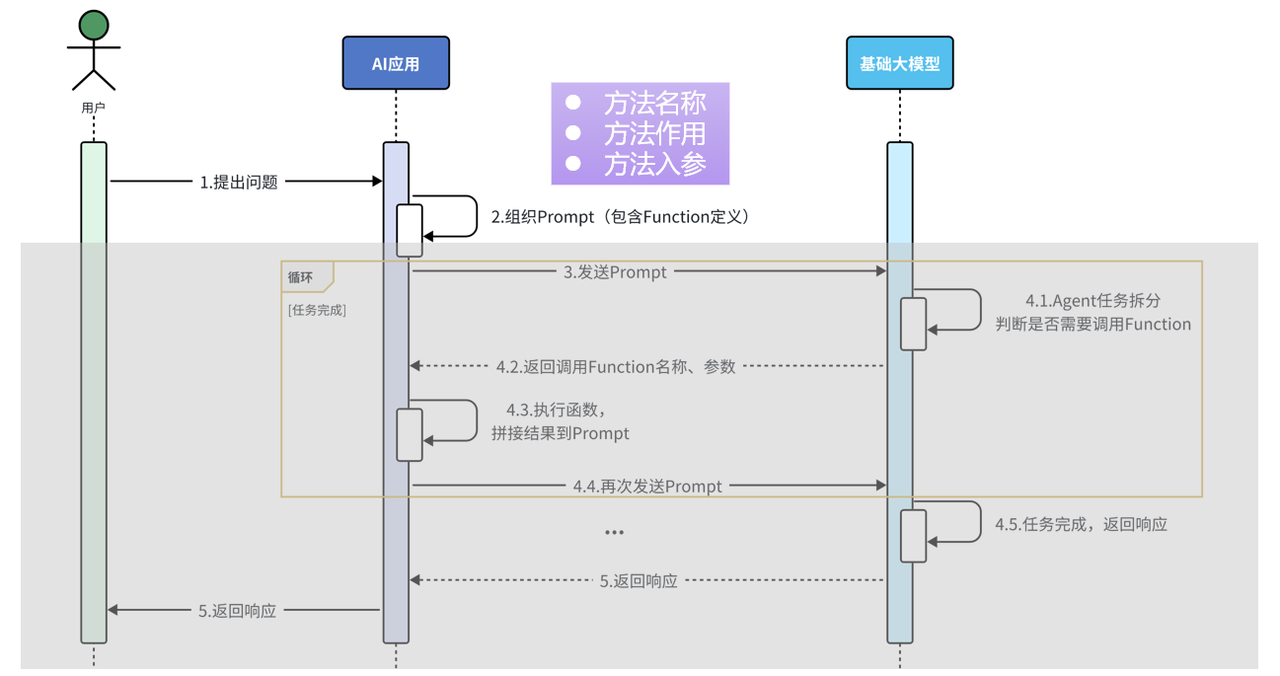
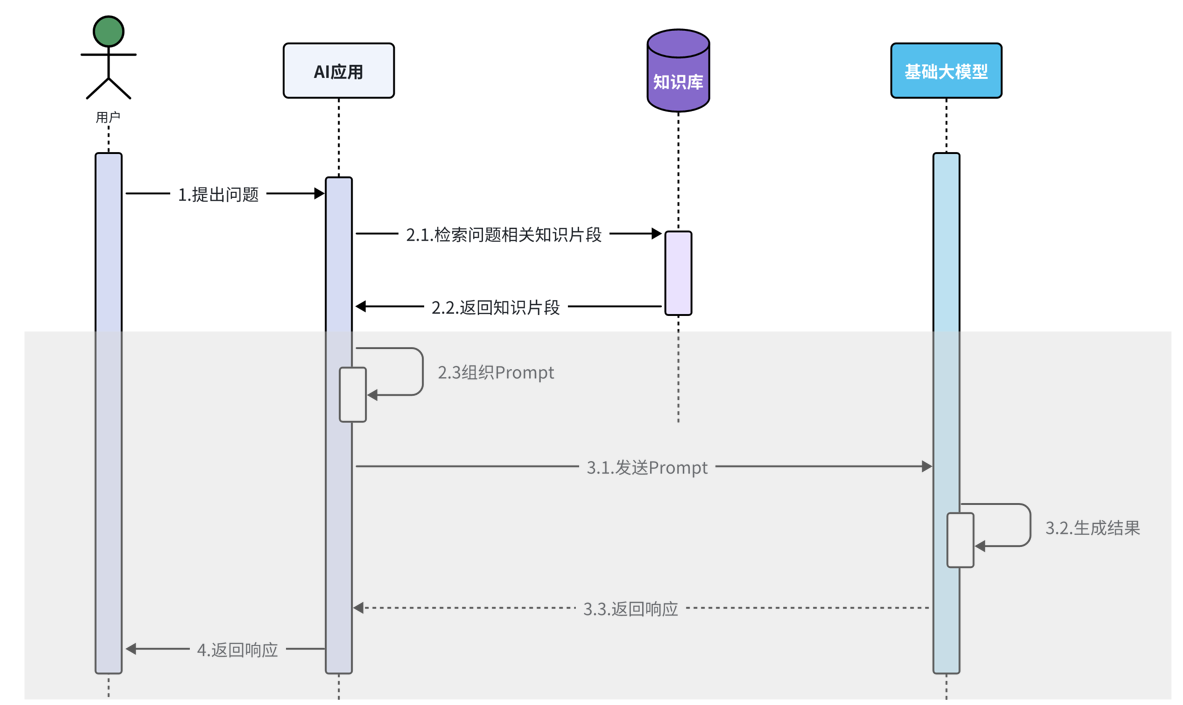
RAG (检索增强生成Retrieval-augmented Generation): 用于从我的私有餐厅数据库中检索信息,解决模型信息过时或不足的问题。
知识文本-分词器 - 向量模型 - 知识库

数据库
根据这些表的组合,可以推测出几个核心的业务流程:
- 用户探店流程:
用户 (tb_user)-> 浏览商铺 (tb_shop)-> 发布探店笔记 (tb_blog)-> 其他用户评论 (tb_blog_comments)。 - 用户关注流程:
用户A (tb_user)-> 关注用户B (tb_user)-> 形成一条关注记录 (tb_follow)。 - 秒杀抢券流程:
用户 (tb_user)-> 在指定时间抢购秒杀券 (tb_seckill_voucher)-> 系统判断库存并创建订单 (tb_voucher_order)->秒杀券库存扣减。 - 用户签到流程:
用户 (tb_user)-> 每日签到 (tb_sign)-> 累积签到天数。