基础数据结构
基础数据结构:String、集合、HashMap、红黑树,及哈希冲突与排序算法。
基础数据结构
String
- String
- 底层是一个
private final``char[]或byte[] - 不可变 final修饰(类、数组) 没有提供修改数组的方法
- 线程安全
- 底层是一个
- StringBuilder
- 可变 无
final - 线程不安全 性能高
- 可变 无
- StringBuffer
- 可变性
- 线程安全 每一个方法使用
sychronized关键字修饰
常见的集合
Collection是接口 Collections是工具类
- Collection接口
- List :ArrayList增删慢 查快 LinkedList增删快 查慢 Vector(线程安全的ArrayList)
- Set:HashSet TreeSet LinkedHashSet
- Map接口
- HashMap TreeMap LinkedHashMap
哈希冲突的解决方式
- 链地址法 数组的每个位置(“桶”,Bucket)不再只存一个元素,而是指向一个“容器”(通常是链表或树)。
- 开放寻址法 继续在哈希表数组内部寻找下一个可用的“空位”。所有元素都必须存放在数组中。
- 线性探测 如果
i被占用,就尝试i+1、i+2、i+3...(直到数组末尾再绕回 0)。 - 平方探测 如果
i被占用,就尝试i+1、i+2、i+3...(直到数组末尾再绕回 0)。 - 双重哈希 使用第二个哈希函数$H_2(key)$ 来计算步长 (step)。
- 线性探测 如果
ArrayList
扩容机制:
- 懒加载,add第一个元素后分配大小为10的数组
- 检查当前
size+1与最小所需容量minCapacity比较 - 如果超过了则扩容1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1); - 数组复制 Arrays.copy
- 旧数组被GC
HashMap
在 JDK 1.7 版本之前, HashMap 数据结构是数组和链表,HashMap通过哈希算法将元素的键(Key)映射到数组中的槽位(Bucket)。如果多个键映射到同一个槽位,它们会以链表的形式存储在同一个槽位上,因为链表的查询时间是O(n),所以冲突很严重,一个索引上的链表非常长,效率就很低了。
默认数组长度为16
所以在 JDK 1.8 版本的时候做了优化,当一个链表的长度超过8,并且数组长度超过64个的时候就转换数据结构,不再使用链表存储,而是使用红黑树,查找时使用红黑树,时间复杂度O(log n),可以提高查询性能,但是在数量较少时,即数量小于6时,会将红黑树转换回链表。
HashMap1.7和HashMap1.8的区别
| 不同点 | hashMap 1.7 | hashMap 1.8 |
|---|---|---|
| 数据结构 | 数组 + 链表 | 数组 + 链表 + 红黑树 |
| 插入数据的方式 | 头插法(多线程同时执行可能破坏链表形成环) | 尾插法 |
| hash 值计算方式 | 9 次扰动处理 (4 次位运算 + 5 次异或) | 2 次扰动处理 (1 次位运算 + 1 次异或) |
| 扩容策略 | 插入前扩容 | 插入后扩容 |
Hash冲突 链地址法
HashMap的扩容机制
hashMap默认的负载因子是0.75,即如果hashmap中的元素个数超过了总容量75%,则会触发扩容,扩容分为两个步骤:
- 第1步是对哈希表长度的扩展(2倍)
- 第2步是将旧哈希表中的数据放到新的哈希表中。
因为我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。省去了重新计算hash值的时间。
如我们从16扩展为32时,具体的变化如下所示:
按位与 (n-1)& Hash值 新索引可以通过简单判断哈希值的某一位来确定,无需重新计算完整哈希
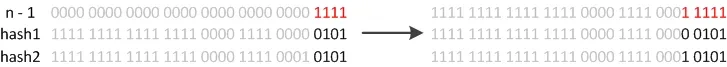
为什么HashMap要用红黑树而不是平衡二叉树?
- 平衡二叉树追求的是一种 “完全平衡” 状态:任何结点的左右子树的高度差不会超过 1,优势是树的结点是很平均分配的。这个要求实在是太严了,导致每次进行插入/删除节点的时候,几乎都会破坏平衡树的第二个规则,进而我们都需要通过左旋和右旋来进行调整,使之再次成为一颗符合要求的平衡树。
- 红黑树不追求这种完全平衡状态,而是追求一种 “弱平衡” 状态:整个树最长路径不会超过最短路径的 2 倍。优势是虽然牺牲了一部分查找的性能效率,但是能够换取一部分维持树平衡状态的成本。与平衡树不同的是,红黑树在插入、删除等操作,不会像平衡树那样,频繁着破坏红黑树的规则,所以不需要频繁着调整,这也是我们为什么大多数情况下使用红黑树的原因。
Put与Get流程
put(K key, V value) 的详细过程
当你调用 map.put(key, value) 时,HashMap 会执行以下步骤:
- 计算 Hash 值: 根据 key 计算出经过扰动函数
(h = key.hashCode()) ^ (h >>> 16)处理后的 hash 值。如果 key 为null,它的 hash 值固定为 0。**h >>> 16**:将 32 位的 hashCode 无符号右移 16 位,把高 16 位降维打击移动到了低 16 位的位置。**^**(异或):将原始的 hashCode 与右移后的结果进行异或运算。
快手面试问题:当n比较小的时候容易发生数据倾斜,是如何解决的
- 判断数组是否为空: 检查底层的 Node 数组(
table)是否为空或长度为 0。如果是,则触发resize()方法进行初始化(默认容量为 16)。 - 计算数组下标并定位槽位(Bucket): 通过
(n - 1) & hash计算出该元素在数组中的索引。 - 处理槽位上的情况:
- 情况 A(无冲突): 如果该索引位置没有任何元素(即为
null),直接新建一个 Node 节点放在这里。 - 情况 B(发生哈希冲突): 如果该位置已经有元素了,说明发生了冲突。此时会进行以下判断:
- 1. 检查第一个节点: 判断该位置第一个节点的 hash 值和 key 是否与当前要插入的 key 完全相同(通过
==或equals()判断)。如果相同,直接覆盖该节点的 value。 - 2. 判断是否为红黑树: 如果第一个节点是
TreeNode类型,说明该槽位已经转化为红黑树。此时调用红黑树的插入方法将节点放入树中(如果树中已存在相同的 key,则覆盖 value)。 - 3. 遍历链表: 如果不是红黑树,说明还是普通的链表结构。此时从头遍历链表:
- 如果在遍历过程中找到相同的 key,则覆盖对应的 value 并结束。
- 如果遍历到链表尾部(即指向
null)还没找到,则将新节点采用尾插法追加到链表末尾。
- 4. 链表转红黑树(树化): 追加新节点后,判断当前链表的长度是否大于等于 8。如果是,且整个 HashMap 的数组长度大于等于 64,则将该链表转化为红黑树(
treeifyBin方法)以提升查询效率;如果数组长度小于 64,则只进行扩容(resize),不转红黑树。
- 1. 检查第一个节点: 判断该位置第一个节点的 hash 值和 key 是否与当前要插入的 key 完全相同(通过
- 情况 A(无冲突): 如果该索引位置没有任何元素(即为
- 检查是否需要扩容: 最后,将 HashMap 的元素总个数(
size)加 1。如果size大于扩容阈值(threshold = 数组容量 * 负载因子,默认负载因子是 0.75),则触发resize()方法进行扩容(通常是扩容为原来的 2 倍)。
get(Object key) 的详细过程
get 的过程相对简单,本质上就是寻找目标节点的过程:
- 计算 Hash 值: 使用与
put相同的扰动函数,计算出被查找 key 的 hash 值。 - 判断数组状态: 如果底层数组为空,或者数组长度为 0,直接返回
null。 - 计算下标并定位: 通过
(n - 1) & hash找到数组中对应的槽位。如果该槽位为空,直接返回null。 - 在槽位中查找元素:
- 检查第一个节点: 如果该槽位第一个节点的 hash 值和 key 与查找的 key 匹配(通过
==或equals()),则直接返回该节点的 value。 - 红黑树查找: 如果第一个节点是
TreeNode(代表这里是一棵红黑树),则按红黑树的查找逻辑(类似二分查找)去搜索,找到匹配的节点则返回 value,否则返回null。 - 链表查找: 如果不是红黑树,则沿着链表往下遍历寻找。只要找到 hash 值和 key 都匹配的节点,就返回其 value;如果遍历完都没找到,返回
null。
- 检查第一个节点: 如果该槽位第一个节点的 hash 值和 key 与查找的 key 匹配(通过
HashMap线程不安全怎么解决
1.7之前 链表死循环 头插法
1.8之后 put覆盖问题
直接加锁 使用HashTable 使用ConcurrentHashMap(cas+synchronized)
ConcurrentHashMap
底层原理和HashMap一致
通过对数组中的某一个头节点Node加锁保证数据更新的一致性
插入新节点(null)的时候用cas
其他时候用Synchronized
Size()方法
通常需要锁定整个Map,然后遍历所有元素进行计数。但这会严重影响并发性能
返回的是一个“估算值”,它在不加锁或尽量少加锁的情况下,提供了一个接近实时的元素数量。
- baseCount 通过 CAS 操作更新到这个
baseCount上 - CounterCell[] counterCells CAS 更新失败时(说明存在并发竞争),为了避免多线程反复自旋在
baseCount这一个点上,线程会转而将计数的增量更新到counterCells数组中的某个随机位置。
返回的时候累加计算s
HashSet TreeSet LinkedHashMap
HashSet 是基于 HashMap 实现的,底层采用 TreeMap 来保存元素
如果哈希值一样,接着会比较 equals 方法 如果 equls 结果为 true ,HashSet 就视为同一个元素。如果 equals 为 false 就不是同一个元素
TreeSet 基于TreeMap实现 TreeMap底层是红黑树
LinkedHashMap 的精妙数据结构。LinkedHashMap 内部维护了两个数据结构:
- 一个哈希表 (Hash Table):这是一个数组,与
HashMap的结构完全相同。它负责保证add,remove,contains操作的 O(1) 高性能。当你查找一个元素时,它通过哈希算法快速定位到数组中的桶(bucket)。 - 一个双向链表 (Doubly-Linked List):这条链表贯穿了哈希表中的所有元素,它负责记录元素的插入顺序。链表有
head(头)和tail(尾)指针。
红黑树
| 特性编号 | 核心要求 | 作用 |
|---|---|---|
| 1 | 节点非红即黑 | 基础颜色定义 |
| 2 | 根节点为黑 | 简化根节点的平衡调整 |
| 3 | 叶子(NIL)节点为黑 | 统一边界,避免颜色判断歧义 |
| 4 | 红节点的子节点必为黑 | 禁止红节点相邻,限制红色路径长度 |
| 5 | 任意节点到叶子的黑节点数相同 | 保证所有路径长度相对平衡,控制树高 |
排序算法?
QuickSort
最坏时间复杂度O(n^2) 当我每次选择pivot都选到最大/最小的那个
平均时间复杂度O(n*logn)
快速排序函数:QuickSort
功能:对数组 A 的区间 [l, r] 执行快速排序。
function QuickSort(A, l, r)
if r ≤ l
return
q = Partition(A, l, r)
QuickSort(A, l, q-1)
QuickSort(A, q+1, r)
随机划分函数:Partition
功能:对数组 A 的区间 [l, r] 执行随机划分(通过随机选主元优化快排性能)。
用j遍历,i为分界线
function Partition(A, l, r)
p = [l, r] 之间的随机整数
Swap(A[p], A[r])
i = l
for j = l to r-1
if A[j] ≤ A[r]
Swap(A[i], A[j])
i = i + 1
Swap(A[i], A[r])
return i三路快排 再加一个指针代表相等的部分 后面只排序小于和大于的部分
归并排序
时间复杂度O(n*logn)
适合给链表排序
# 将A[l..r-1]进行排序
function MERGESORT(A, l, r)
if r-l ≤ 1
return
m = ⌊(l + r) / 2⌋
MERGESORT(A, l, m)
MERGESORT(A, m, r)
MERGE(A, l, m, r)
# 合并有序数组A[l..m-1]和A[m..r-1]
function MERGE(A, l, m, r)
L = A[l..m-1].copy()
R = A[m..r-1].copy()
L.append(+∞)
R.append(+∞)
i = 0, j = 0, k = l
while k ≠ r
if L[i] ≤ R[j]
A[k] = L[i]
i = i + 1
else
A[k] = R[j]
j = j + 1
k = k + 1